By Sertalp B. Cay | December 25, 2018
In this post, I will show how you can use Python to gather content and create a simple web page around it. See the first part to learn how to register an app to Reddit API and get started.
Setup
I often use PyCharm or Jupyter notebook for Python, but any Python environment will do the trick. You need to have a Reddit app id and app secret already at hand for this part. A basic knowledge of HTML and CSS might be useful, but not required for the high level content.
I will write a script which will search “puppy” related subreddits and show their top posts as a gallery. This project might be enough to trigger your cute aggression if you are into dogs.
Overview

I have shown a basic introduction to Reddit API in the previous part. Here are 4 simple steps we will follow:
- Find subreddits related to puppies\
GET /subreddits/search - Get list of posts for every subreddit\
GET /top - Filter and collect image links as an HTML code
- Finally, display (and save) the HTML content
GET requests are passive members of the RESTful APIs.
So, the script won’t publish anything, but instead will return the content that you can parse.
Querying the subreddit names
The first order of business is to get subreddit names that you need to parse. You can use Reddit’s search function through the API:
payload = {'q': 'puppies', 'limit': 5}
response = requests.get(api_url + '/subreddits/search', headers=headers, params=payload)
js = response.json()The variable js is a nested dictionary, which includes the response we got from Reddit.
We can see the keys of the dictionary
print(js.keys())dict_keys(['kind', 'data'])
You can get familiar with the responses, but visualizing it helps immensely.
Using your favorite JSON viewer (https://jsoneditoronline.org/, https://codebeautify.org/jsonviewer, http://jsonviewer.stack.hu/) copy the content response.text to visualize the JSON response.
Reddit’s response include two objects.
The object kind shows, well, what kind of data that data object has.
If it is a listing, then the data object includes two strings, before and after which will be used to navigate.
After we finish parsing the first page, for example, we will use the after parameter to request the second page.
{
"kind": "Listing",
"data": {
"modhash": null,
"dist": 5,
"children": [...],
"after": "t5_2tjl7",
"before": null
}
}Here, the data you can use is inside the children array.
Reddit makes our lives easy here by giving us how many elements the children array has "dist": 5.
Let’s see what the first child includes:
"children": [
{
"kind": "t5",
"data": {
"display_name": "puppies",
"display_name_prefixed": "r/puppies",
...
}
},
...
]The data object has a lot fields.
I will only use display_name in this step.
A JSON viewer shows that the display_name can be accessed using the following breadcrumbs: data > children > i > data > display_name.
Now you can gather all subreddit names as follows:
sr = []
for i in range(js['data']['dist']):
sr.append(js['data']['children'][i]['data']['display_name'])
print(sr)['puppies', 'aww', 'dogpictures', 'corgi', 'lookatmydog']
Collecting posts
Now that we have a list of subreddits, let us continue with collecting top 5 images from subreddits in our pool.
For this purpose, we will get top posts of all time from this subreddit. Remember that, some subreddits and their top posts may not be related to our search term, but our purpose here is to simply display a list of top posts from related subreddits.
The API request /r/(subreddit)/top – where subreddit will be replaced with the subreddit name – will give us the top posts.
Simply replace subreddit with the subreddit names you stored in sr variable.
Before going any further, print a simple response to understand the structure:
payload = {'t': 'all'}
r = requests.get(api_url + '/r/puppies/top', headers=headers, params=payload)
print(r.text){
"kind": "Listing",
"data": {
"modhash": null,
"dist": 25,
"children": [
{
"kind": "t3",
"data": {
"title": "Recently at the airport",
"url": "http://imgur.com/qPjptrd.jpg",
"thumbnail": "https://b.thumbs.redditmedia.com/bJxCSi2BHocxt0RlUvfk2ibVIKhpniqFL7_j-sCEs-Y.jpg",
"approved_at_utc": null,
"subreddit": "puppies",
"selftext": "",
...
}
},
...
],
"after": "t3_7s49s5",
"before": null
}
}
As you see from the JSON response, you need to access the data in this order: data > children > i > data > title.
I will only use title, thumbnail and url here, but it is a good idea to check what kind of data Reddit returns for future projects.
You can iterate over all children and save the thumbnails inside an HTML code. This HTML code can be printed if you are using Jupyter. I will also show how it can be saved as an HTML page. If you are not familiar with HTML, perhaps it is a good idea to check the basics at your earliest convenience, as it is a very useful skill especially nowadays. The HTML tags I use following are as follows:
h3for printing titlesdivfor grouping and stylingspanfor grouping HTML elements togetherafor creating linksimgfor displaying images
The following code shows the title of the subreddit, and then puts 5 top images next to each other. It’s a good idea to use thumbnails instead of full images since you only need to show a small photo in the gallery. When user hovers, it will show the original poster’s title and clicking will take user to the full image (or URL).
payload = {'t': 'all', 'limit': 5}
imghtml = ''
for s in sr:
imghtml += '<h3 style="clear:both">{}</h3><div>'.format(s)
r = requests.get(api_url + '/r/{}/top'.format(s), headers=headers, params=payload)
js = r.json()
for i in range(js['data']['dist']):
if js['data']['children'][i]['data']['thumbnail'] == '':
continue
imghtml += '<span style="float:left"><a href="{}"><img src="{}" title="{}" target="_blank" \></a></span>'.format(
js['data']['children'][i]['data']['url'],
js['data']['children'][i]['data']['thumbnail'],
js['data']['children'][i]['data']['title'],
)
imghtml += '</div>'Here, the GET request to /r/(subreddit)/top returns the top posts from that subreddit.
I passed time period t=all and a limit on number of posts from each subreddit limit=5 for the query.
At the end imghtml should have the HTML code you need to display.
Result
We have arrived the final step of our short and hopefully to-the-point tutorial. Images can be displayed in Jupyter notebook as follows:
from IPython.core.display import display, HTML
display(HTML(imghtml))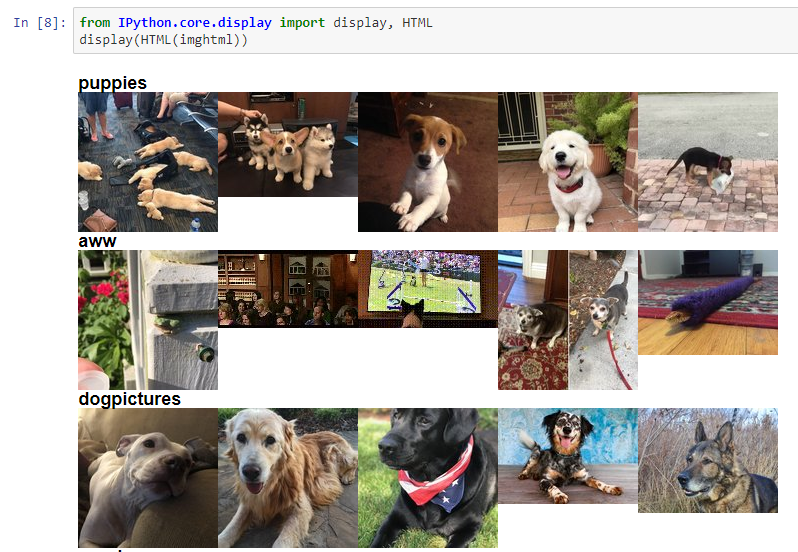
The functions we used display and HTML are specific to Jupyter.
If you are using a different tool to write your Python code, it makes sense to write the HTML code into a page.
with open("puppies.html", "w", encoding='utf-8') as html_page:
html_page.write(imghtml)Now, you can navigate the folder your Python code lives and open the appropriately named puppies.html page.
See a preview here.
Closing
There is a ton of information that I could not covered in here to keep this post to the point. I was hoping to write a trivia game, where you see a photo and try to guess the subreddit it was shared, but I have to skip it for now. I might do it in another iteration, hopefully.
If you have enjoyed the tutorial check my Jupyter notebook to see a full example, where a web page is generated out of a given search query. In one of the upcoming blog posts, I will show you how to write a Reddit bot, that will parse information from two separate APIs and post comments on Reddit.
